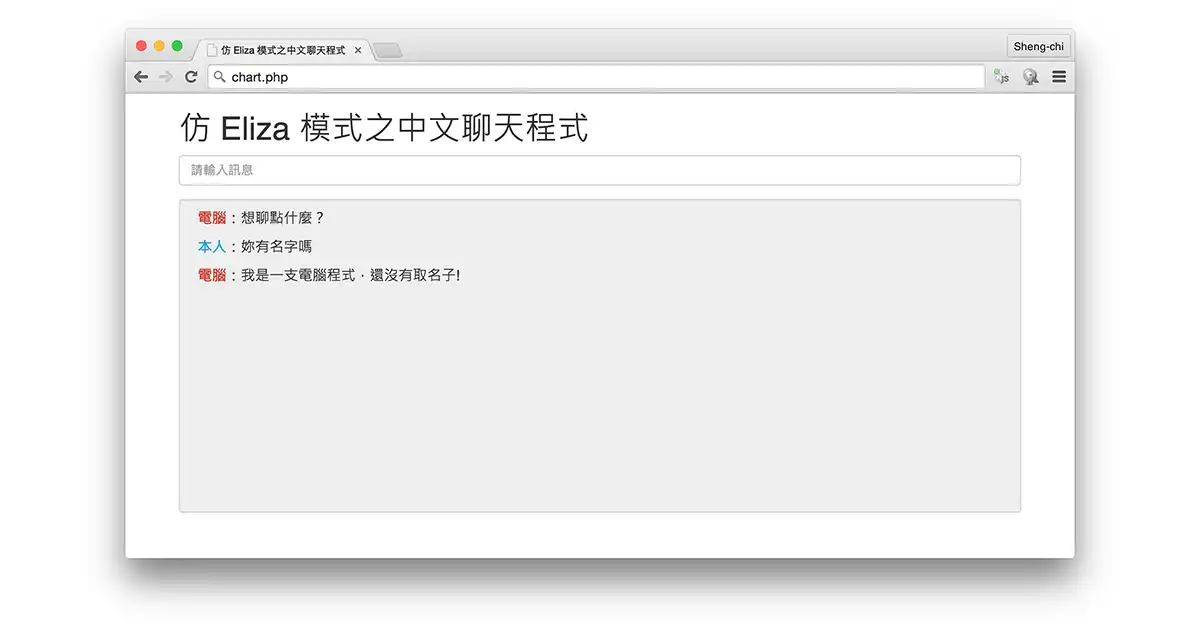
仿 Eliza 模式之中文聊天程式
人工智慧前陣子本來在尋找電腦語音合成的相關知識,無意間發現了這個既有趣又非常好理解的聊天程式 Eliza。Eliza 是一個早期人工智慧聊天程式,於 1966 年由 Joseph Weizenbaum 在麻省理工學院所寫的程式,它使用一種基於模板的識別演算法來模仿心理治療師 Carl R. Rogers 的精神治療法,與使用者進行人類般的對話,被認為是現代聊天機器人的鼻祖。
大家可以先連結以下網址操作看看,再繼續閱讀本文。
演算法
ELIZA 演算法主要分為五個步驟:
- 步驟ㄧ:讀取使用者輸入
- 步驟二:使用模板匹配使用者輸入
- 步驟三:替換匹配到的詞
- 步驟四:將你替換成我,將我替換成你
- 步驟五:輸出電腦答覆
上述的演算法,大概可以寫成以下虛擬碼來表示:
switch (input) {
case '我喜歡%S':
output = '你爲什麼喜歡%S';
break;
case '可不可以%S':
output = '你確定要%S';
break;
default:
output = '請繼續說下去';
break;
}
output = replace('我', '你') and replace('你', '我');
比如說我們輸入是我喜歡看電影,根據上面演算法,電腦會回覆我們你爲什麼喜歡看電影,看起來似乎蠻合理的。在步驟四需要替換你跟我這兩個字,是因為在某些特定情況下我們可能會輸入兩個我之類的句子,例如我喜歡我的車子,如果這時候不執行步驟四的話,便會得到你爲什麼喜歡我的車子,這明顯是個不合理的回答。假如在模板中都找不到可匹配的字詞的話,就直接回覆一段句子以讓使用者繼續輸入。
規則庫
看完上面的內容,應該不難發現這程式最難的並不是程式邏輯本身,而在於建立模板規則,需要累積一些句子,並分析語句結構,這部分我並沒有花時間去研究,而是直接使用自己動手設計交談機器人 (Eliza 中文版) - 使用 Java 這篇文章使用的規則,並額外加入一些我臨時想到的規則。
[
{'Q': ['謝謝'], 'A': ['不客氣!']},
{'Q': ['對不起', '抱歉', '不好意思'], 'A': ['別說抱歉!', '別客氣,儘管說!']},
{'Q': ['可否', '可不可以'], 'A': ['你確定想*?']},
{'Q': ['我想'], 'A': ['你為何想*?']},
{'Q': ['我要'], 'A': ['你為何要*?']},
{'Q': ['你是'], 'A': ['你認為我是*?']},
{'Q': ['認為', '以為'], 'A': ['為何說*?']},
{'Q': ['覺得'], 'A': ['為何覺得*?']},
{'Q': ['感覺'], 'A': ['常有這種感覺嗎?']},
{'Q': ['為何不'], 'A': ['你希望我*!']},
{'Q': ['是否'], 'A': ['為何想知道是否*?']},
{'Q': ['不能'], 'A': ['為何不能*?', '你試過了嗎?', '或許你現在能*了呢?']},
{'Q': ['我是'], 'A': ['你好,久仰久仰!']},
{'Q': ['甚麼', '什麼', '何時', '誰', '哪裡', '如何', '為何', '因何'], 'A': ['為何這樣問?', '為何你對這問題有興趣?', '你認為答案是甚麼呢?', '你認為如何呢?', '你常問這類問題嗎?', '這真的是你想知道的嗎?', '為何不問問別人?', '你曾有過類似的問題嗎?', '你問這問題的原因是甚麼呢?']},
{'Q': ['原因'], 'A': ['這是真正的原因嗎?', '還有其他原因嗎?']},
{'Q': ['理由'], 'A': ['這說明了甚麼呢?', '還有其他理由嗎?']},
{'Q': ['你好', '嗨', '您好'], 'A': ['你好,有甚麼問題嗎?']},
{'Q': ['或許'], 'A': ['你好像不太確定?']},
{'Q': ['不曉得', '不知道'], 'A': ['為何不知道?', '在想想看,有沒有甚麼可能性?']},
{'Q': ['不想', '不希望'], 'A': ['有沒有甚麼辦法呢?', '為何不想*呢?', '那你希望怎樣呢?']},
{'Q': ['想', '希望'], 'A': ['為何想*呢?', '真的想*?', '那就去做阿?為何不呢?']},
{'Q': ['不'], 'A': ['為何不*?', '所以你不*?']},
{'Q': ['請'], 'A': ['我該如何*呢?', '你想要我*嗎?']},
{'Q': ['你'], 'A': ['你真的是在說我嗎?', '別說我了,談談你吧!', '為何這麼關心我*?', '不要再說我了,談談你吧!', '你自己*']},
{'Q': ['總是', '常常'], 'A': ['能不能具體說明呢?', '何時?']},
{'Q': ['像'], 'A': ['有多像?', '哪裡像?']},
{'Q': ['對'], 'A': ['你確定嗎?', '我了解!']},
{'Q': ['性別'], 'A': ['我是一支電腦程式,我沒有性別!']},
{'Q': ['名字'], 'A': ['我是一支電腦程式,還沒有取名子!']},
{'Q': ['朋友'], 'A': ['多告訴我一些有關他的事吧!', '你認識他多久了呢?']},
{'Q': ['電腦'], 'A': ['你說的電腦是指我嗎?']},
{'Q': ['難過'], 'A': ['別想它了', '別難過', '別想那麼多了', '事情總是會解決的']},
{'Q': ['高興'], 'A': ['不錯ㄚ', '太棒了', '這樣很好ㄚ']},
{'Q': ['是阿', '是的'], 'A': ['甚麼事呢?', '我可以幫助你嗎?', '我希望我能幫得上忙!']},
{'Q': [''], 'A': ['我了解', '我能理解', '還有問題嗎?', '請繼續說下去', '可以說的更詳細一點嗎?', '這樣喔!我知道!', '然後呢?發生甚麼事?', '再來呢?可以多說一些嗎', '接下來呢?', '可以多告訴我一些嗎?', '多談談有關你的事,好嗎?', '想多聊一聊嗎', '可否多告訴我一些呢?']}
];
上方模板的使用方式可能會與上述虛擬碼有些不同,基本上為逐一比對陣列中 Q 陣列出現的字是否同樣出現在 input ,如果有便從 A 陣列隨機找一個句子來回應,最後面的 'Q': [''] 即表示在找不到任何匹配字詞的情況下,系統預設的回答。
到這裡就介紹完 Eliza 的運作邏輯,是不是還蠻容易理解的呢?雖然我認為這個程式並不是真的很有智慧,嚴格來講只是一種模式的應用。儘管 Eliza 的運作方式非常簡單,但它在當時卻是一個非常有創意和有趣的應用,並且對於人工智慧聊天機器人的發展起了一定的推動作用。現今的聊天機器人通常使用更複雜的演算法和技術,但 Eliza 依然是一個非常經典的範例。
參考資料
- 自己動手設計交談機器人 (Eliza 中文版) - 使用 Java
- Wikipedia:ELIZA










0 則留言