
網路程式著名的 C10K 問題
軟體開發幾年前,我曾接觸到一個大型的測驗系統。當時,老闆要求調整系統以提升網站瞬間承載流量,希望能夠同時負荷 15000 人上線使用網站。當時我對這個問題一無所知,再加上公司使用的伺服器規格還算不錯,所以就草率地答應了老闆的要求。最終,我修改了 Apache 及 Linux 的一些設定,勉強將單台伺服器的瞬間承載流量撐到了 4000~5000 人,但是這明顯不足以應對老闆的需求。所幸,當時老闆沒有要求要單台伺服器,因此我用了 4 台伺服器做負載平衡,最終還是達到了要求。
隔年老闆再次提到這個問題,於是我上網搜尋相關資料才發現網路程式存在著 C10K 的問題。雖然這個問題早已被提出多年,且國外也有人提出了支援更高連線數的方案,所以現在談這個似乎已經有點過時了,不過目前主流的 Apache 及 Tomcat 在預設情況下依然存在這樣的問題。過去在網路不普及的年代,C10K 的問題並不顯著,甚至完全不會發生,然而,現在網站開發都喜歡使用 AJAX,瀏覽器同一時間隨便都能產生 10 幾條連線,因此 C10K 的問題才越來越顯著。
簡而言之,C10K 問題是指當網站同時處理 10000 個以上的連線數時,很多設計不良的網路服務性能會急速下降,且該問題無法透過升級記憶體或 CPU 等硬體設備得到改善。而這與網頁伺服器的 I/O 模型架構有關,I/O 操作是電腦重要的工作之一,根據操作的裝置不同還可以分為許多不同種類,例如磁碟 I/O、記憶體 I/O、網路 I/O,但是本篇我們著重於網路 I/O 的部分進行討論。
同步、非同步、阻塞和非阻塞
在說明 I/O 模型之前,我們先來瞭解一下網路程式常使用的四種I/O類型:
- 同步 (synchronous)
- 指程序 (Process) 主動對 I/O 提出請求,並等待 I/O 操作完畢,才能繼續工作,例如 C/S 模式。
- 非同步 (Asynchronous)
- 指程序主動對 I/O 提出請求後,便可繼續處理其他工作,待 I/O 操作完畢後,會通知程序已經處理完畢,例如 AJAX 非同步請求。
- 阻塞 (blocking)
- 指執行緒 (Thread) 存取資料時,如果資料尚未就緒,執行緒就會一直等待,直到資料準備好。
- 非阻塞 (non-blocking)
- 指執行緒存取資料時,如果資料尚未就緒,執行緒不會等待,而是直接回傳一個狀態碼。
有些時候同步與非同步、阻塞與非阻塞的概念很容易混肴,其實重點在於您所描述的對象是什麼,在網路 I/O 中,同步描述的是函數外部存取資料的機制,是否需要等到函數回傳資料後再繼續執行;而阻塞描述的是函數內部 I/O 實現的方式,當沒有資料時函數內部是否繼續等待資料,還是直接回傳狀態碼。
另外,同步與非同步解釋,在 UNIX Network Programming 電子書上有看到以下定義,提供給大家參考。
POSIX defines these two terms as follows:
- A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes.
- An asynchronous I/O operation does not cause the requesting process to be blocked.
根據書上翻譯,該定義是由 POSIX 所定義的,但我找不到原始定義的文章,如大家有找到,再麻煩通知我,謝謝。
網路程式使用的 I/O 模型
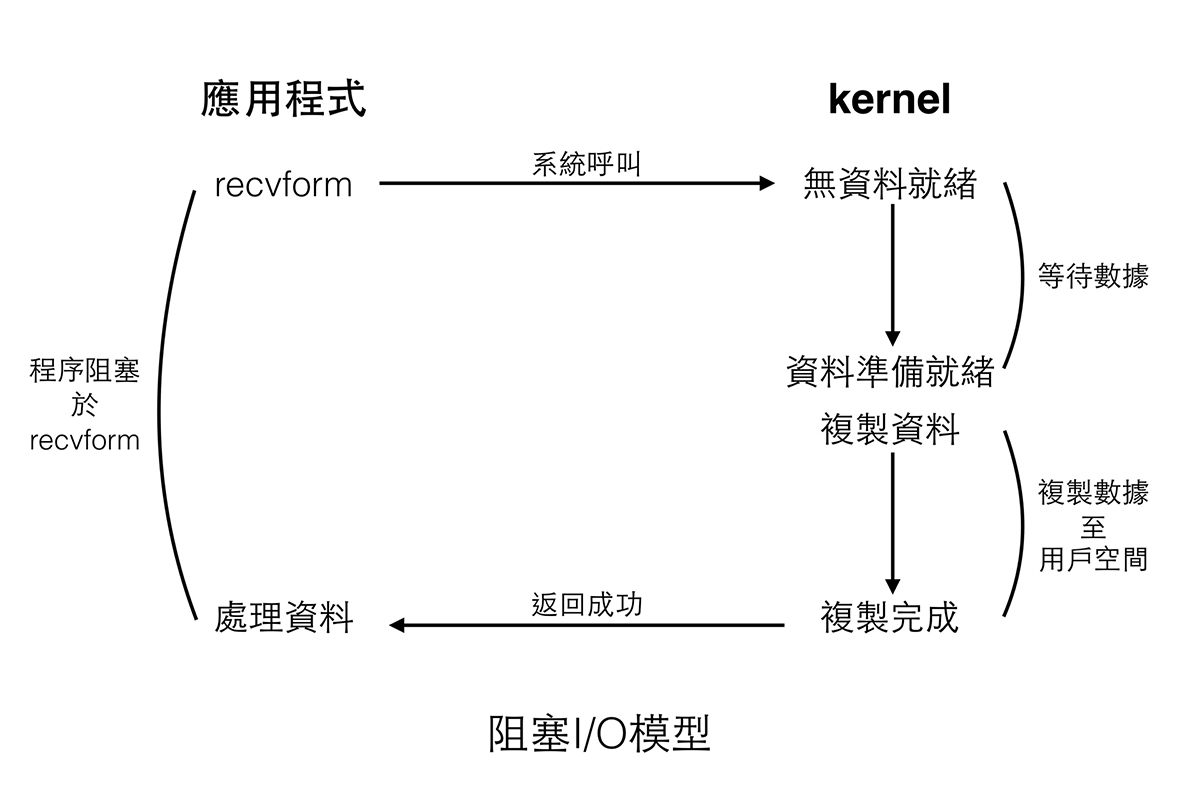
阻塞 I/O (bloking I/O)
程序對 I/O 提出請求時,如果 I/O 不能立即完成操作,程序與執行緒進入等待狀態,直到 I/O 操作完成。在這個模型中執行緒實際等待的時間包含兩部分,一個是等待資料就緒,另一個是等待資料複製完成,對於網路 I/O 來說,等待資料就緒的時間顯然要長一點。在這個模型當中如果平行連線數過多,通常會搭配多執行緒使用。這是最簡單也最直覺的模型,也由於簡單,所以被廣泛的使用。
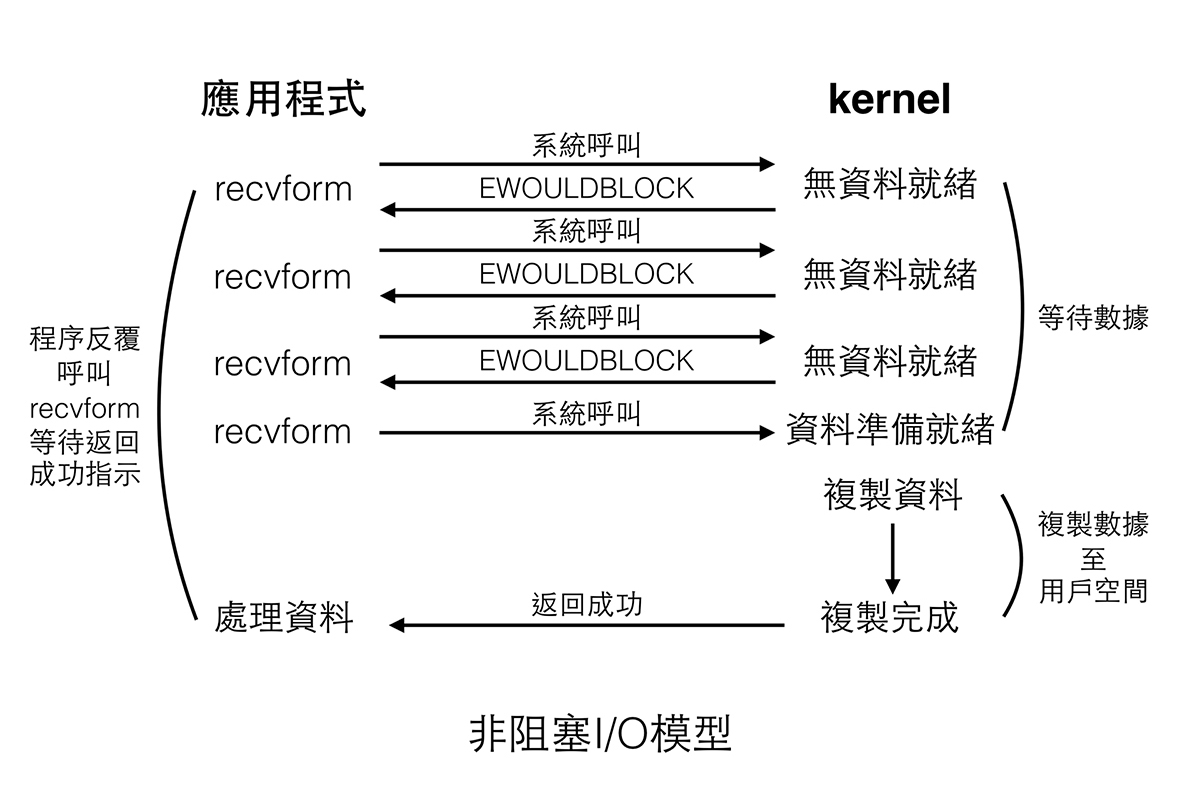
非阻塞 I/O (non-bloking I/O)
程序對 I/O 提出請求時,如果 I/O 不能立即完成操作,執行緒會立即返回狀態碼,此時程序可以先處理別的請求後再向 I/O 詢問資料準備好了沒,反覆此過程,直到資料準備就緒,這個過程被稱為輪詢 (Polling)。在這個模型當中,在資料準備階段程序與執行緒皆不阻塞,最大的好處是在同一個執行緒可同時處理多個 I/O 操作,但需要消耗大量 CPU 時間來做輪詢的動作,要注意的是,資料複製階段程序依然處於阻塞。
多路複用 I/O (multiplexing I/O)
在非阻塞 I/O 模型中,當伺服器收到多個連線時,就必須輪流對每個執行緒詢問資料是否準備就緒,不管這些執行緒是否有接收到資料,都必須詢問一遍,這顯然不是好的策略。多路複用 I/O 的出現就是為了改善這個問題,在多路複用 I/O 模型中,程序提出請求時,執行緒透過某種方式來監視資源是否準備就緒,並可快速得到就緒的資源符號,然後只針對就緒的資源做處理,與非阻塞 I/O 不同的是,多路複用 I/O 可同時等待多個資源,待一部分資源到來,便可先行處理,而無需等到所有的資源到達。由於平台歷史的原因,多路複用 I/O 有很多不同的實作,其效能也有些微的差異,常見的有 select、poll、SIGIO、epoll 及 kqueue。
select 與 poll 本質上沒有什麼不同,當程序呼叫 select 時,實際上是讓 select 監視所需的資料,此時無論有多少連線處於活躍狀態或有多少檔案準備就緒,select 都會對其做一次線性掃描,當資料準備就緒之後 select 會通知程序,此時如果程序沒有對其進行 I/O 操作,下次呼叫 select 的時候,將再次報告這些檔案已準備就緒,因此一般不會有遺失的問題,該方式被稱為水平觸發 (Level Triggered)。select 的一個缺點在於單一執行緒能監視的檔案描述符號是有上限的,通常為 1024,而 poll 則沒有這個限制。兩者共同存在的缺點是,當大量的檔案描述符號被整體複製於程序與核心的位址空間,系統資源的消耗會隨著檔案描述符號的數量增加而增加。我們常用的 Apache 即是使用 select 模型,因此才會有 C10K 的問題。
SIGIO 被稱為訊息驅動 (signal-driven I/O),它透過即時訊號來實作 select/poll 的通知方法,不同的是 select/poll 在資料準備就緒時會一直通知程序,直到程序讀寫資源為止;而 SIGIO 只會通知一次,如果程序不做任何讀寫的話,他也不會再次通知,該方式稱為邊緣觸發 (Edge Triggered)。其缺點是代表事件的訊號是由核心事件佇列來維護,訊號按照順序進行通知,這可能導致訊號到達時,該事件已經過期了,有造成遺失的問題,另外事件佇列也是有長度限制的。
epoll 實作於 Linux 2.6;kqueue 實作於 FreeBSD,兩者一樣都可以設定水平觸發或邊緣觸發,預設情況下 epoll 使用水平觸發,同時使用記憶體映射技術來解決 select/poll 中大量描述符號被整體複製時資源消耗過大的問題,且 epoll 直接由核心支援,被公認為 Linux 2.6 下效能最好的多路複用 I/O。Nginx 即是使用 epoll 模型且使用邊緣觸發模式。

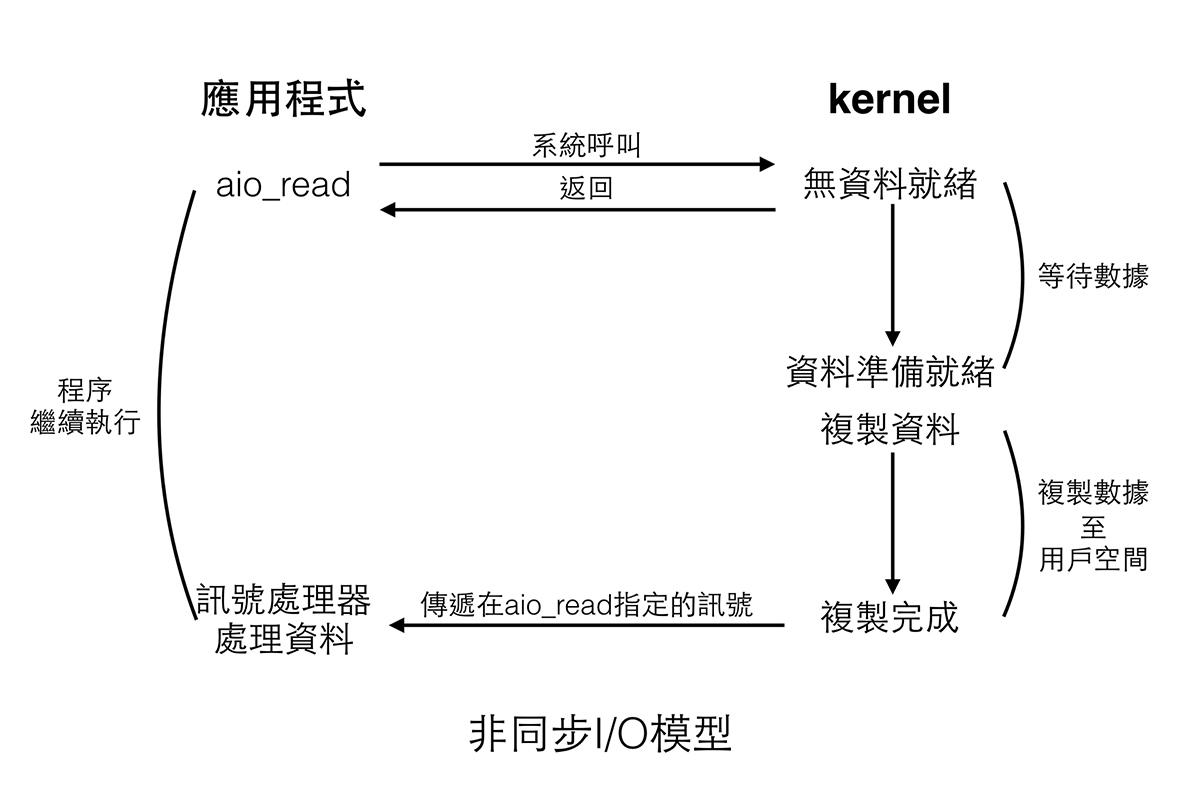
非同步 I/O (asynchronous I/O)
程序對 I/O 提出請求時,無論資料是否準備好,都直接返回,然後程序就可以去做別的事情了,待資料準備就緒,內核直接複製數據,然後通知程序,該模型在資料準備與資料複製都是非阻塞的。
了解上面的 I/O 模型的差異之後,如果大家想要進一步瞭解這些模型效能上的差異,我會建議大家看一下巨型網站大師親自指導:建立極速 Web 站台的祕密這本書,這本書在 3.7 章伺服器平行策略有針對不同模型的實驗紀錄及數據。您或許會好奇為什麼 Apache 不使用 epoll 模式,那是因為 Apache 很多模組都是針對 select 模型而設計的,要全面改成 epoll 模型,想必是一件大工程吧。
參考資料
- 原文詳細說明:The C10K problem
- Wikipedia:The C10K problem
- 書籍:巨型網站大師親自指導:建立極速 Web 站台的祕密, ISBN:9789865836047, page3-40~page3-72
- 電子書:UNIX Network Programming, ISBN:0131411551, 6.2 I/O Models






0 則留言